Определение эмпирической функции распределения
Пусть $X$ -- случайная величина. $F(x)$ - функция распределения данной случайной величины. Будем проводить в одних и тех же независимых друг от друга условий $n$ опытов над данной случайной величиной. При этом получим последовательность значений $x_1,\ x_2\ $, ... ,$\ x_n$, которая и называется выборкой.
Определение 1
Каждое значение $x_i$ ($i=1,2\ $, ... ,$ \ n$) называется вариантой.
Одной из оценок теоретической функции распределения является эмпирическая функция распределения.
Определение 3
Эмпирической функцией распределения $F_n(x)$ называется функция, которая определяет для каждого значения $x$ относительную частоту события $X \
где $n_x$ - число вариант, меньших $x$, $n$ -- объем выборки.
Отличие эмпирической функции от теоретической состоит том, что теоретическая функция определяет вероятность события $X
Свойства эмпирической функции распределения
Рассмотрим теперь несколько основных свойств функции распределения.
Область значений функции $F_n\left(x\right)$ -- отрезок $$.
$F_n\left(x\right)$ неубывающая функция.
$F_n\left(x\right)$ непрерывная слева функция.
$F_n\left(x\right)$ кусочно-постоянная функция и возрастает только в точках значений случайной величины $X$
Пусть $X_1$ -- наименьшая, а $X_n$ -- наибольшая варианта. Тогда $F_n\left(x\right)=0$ при ${x\le X}_1$и $F_n\left(x\right)=1$ при $x\ge X_n$.
Введем теорему, которая связывает между собой теоретическую и эмпирическую функции.
Теорема 1
Пусть $F_n\left(x\right)$ -- эмпирическая функция распределения, а $F\left(x\right)$ -- теоретическая функция распределения генеральной выборки. Тогда выполняется равенство:
\[{\mathop{lim}_{n\to \infty } {|F}_n\left(x\right)-F\left(x\right)|=0\ }\]
Примеры задач на нахождение эмпирической функции распределения
Пример 1
Пусть распределение выборки имеет следующие данные, записанные с помощью таблицы:
Рисунок 1.
Найти объем выборки, составить эмпирическую функцию распределения и построить её график.
Объем выборки: $n=5+10+15+20=50$.
По свойству 5, имеем, что при $x\le 1$ $F_n\left(x\right)=0$, а при $x>4$ $F_n\left(x\right)=1$.
Значение $x
Значение $x
Значение $x
Таким образом, получаем:
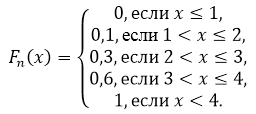
Рисунок 2.
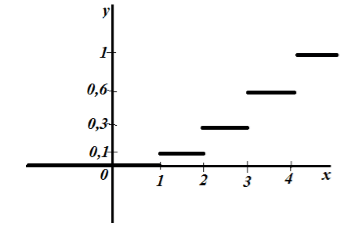
Рисунок 3.
Пример 2
Из городов центральной части России случайным образом выбрано 20 городов, для которых получены следующие данные по стоимости проезда в общественном транспорте: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14, 15, 13, 13, 12, 12, 15, 14, 14.
Составить эмпирическую функцию распределения данной выборки и построить её график.
Запишем значения выборки в порядке возрастания и посчитаем частоту каждого значения. Получаем следующую таблицу:
Рисунок 4.
Объем выборки: $n=20$.
По свойству 5, имеем, что при $x\le 12$ $F_n\left(x\right)=0$, а при $x>15$ $F_n\left(x\right)=1$.
Значение $x
Значение $x
Значение $x
Таким образом, получаем:
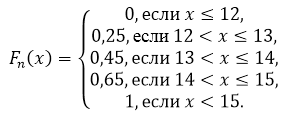
Рисунок 5.
Построим график эмпирического распределения:

Рисунок 6.
Оригинальность: $92,12\%$.
Определение эмпирической функции распределения
Пусть $X$ -- случайная величина. $F(x)$ - функция распределения данной случайной величины. Будем проводить в одних и тех же независимых друг от друга условий $n$ опытов над данной случайной величиной. При этом получим последовательность значений $x_1,\ x_2\ $, ... ,$\ x_n$, которая и называется выборкой.
Определение 1
Каждое значение $x_i$ ($i=1,2\ $, ... ,$ \ n$) называется вариантой.
Одной из оценок теоретической функции распределения является эмпирическая функция распределения.
Определение 3
Эмпирической функцией распределения $F_n(x)$ называется функция, которая определяет для каждого значения $x$ относительную частоту события $X \
где $n_x$ - число вариант, меньших $x$, $n$ -- объем выборки.
Отличие эмпирической функции от теоретической состоит том, что теоретическая функция определяет вероятность события $X
Свойства эмпирической функции распределения
Рассмотрим теперь несколько основных свойств функции распределения.
Область значений функции $F_n\left(x\right)$ -- отрезок $$.
$F_n\left(x\right)$ неубывающая функция.
$F_n\left(x\right)$ непрерывная слева функция.
$F_n\left(x\right)$ кусочно-постоянная функция и возрастает только в точках значений случайной величины $X$
Пусть $X_1$ -- наименьшая, а $X_n$ -- наибольшая варианта. Тогда $F_n\left(x\right)=0$ при ${x\le X}_1$и $F_n\left(x\right)=1$ при $x\ge X_n$.
Введем теорему, которая связывает между собой теоретическую и эмпирическую функции.
Теорема 1
Пусть $F_n\left(x\right)$ -- эмпирическая функция распределения, а $F\left(x\right)$ -- теоретическая функция распределения генеральной выборки. Тогда выполняется равенство:
\[{\mathop{lim}_{n\to \infty } {|F}_n\left(x\right)-F\left(x\right)|=0\ }\]
Примеры задач на нахождение эмпирической функции распределения
Пример 1
Пусть распределение выборки имеет следующие данные, записанные с помощью таблицы:
Рисунок 1.
Найти объем выборки, составить эмпирическую функцию распределения и построить её график.
Объем выборки: $n=5+10+15+20=50$.
По свойству 5, имеем, что при $x\le 1$ $F_n\left(x\right)=0$, а при $x>4$ $F_n\left(x\right)=1$.
Значение $x
Значение $x
Значение $x
Таким образом, получаем:
Рисунок 2.
Рисунок 3.
Пример 2
Из городов центральной части России случайным образом выбрано 20 городов, для которых получены следующие данные по стоимости проезда в общественном транспорте: 14, 15, 12, 12, 13, 15, 15, 13, 15, 12, 15, 14, 15, 13, 13, 12, 12, 15, 14, 14.
Составить эмпирическую функцию распределения данной выборки и построить её график.
Запишем значения выборки в порядке возрастания и посчитаем частоту каждого значения. Получаем следующую таблицу:
Рисунок 4.
Объем выборки: $n=20$.
По свойству 5, имеем, что при $x\le 12$ $F_n\left(x\right)=0$, а при $x>15$ $F_n\left(x\right)=1$.
Значение $x
Значение $x
Значение $x
Таким образом, получаем:
Рисунок 5.
Построим график эмпирического распределения:
Рисунок 6.
Оригинальность: $92,12\%$.
Выборочная средняя.
Пусть для изучения генеральной совокупности относительно количественного признака Х извлечена выборка объема n.
Выборочной средней называют среднее арифметическое значение признака выборочной совокупности.
![]()
Выборочная дисперсия.
Для того, чтобы наблюдать рассеяние количественного признака значений выборки вокруг своего среднего значения, вводят сводную характеристику- выборочную дисперсию.
Выборочной дисперсией называют среднее арифметическое квадратов отклонения наблюдаемых значений признака от их среднего значения.
Если все значения признака выборки различны, то

Исправленная дисперсия.
Выборочная дисперсия является смещенной оценкой генеральной дисперсии, т.е. математическое ожидание выборочной дисперсии не равно оцениваемой генеральной дисперсии, а равно
![]()
Для исправления выборочной дисперсии достаточно умножить ее на дробь
Выборочный коэффициент корреляции находится по формуле

где - выборочные средние квадратические отклонения величин и .
Выборочный коэффициент корреляции показывает тесноту линейной связи между и : чем ближе к единице, тем сильнее линейная связь между и .
23. Полигоном частот называют ломаную линию, отрезки которой соединяют точки . Для построения полигона частот на оси абсцисс откладывают варианты , а на оси ординат – соответствующие им частоты и соединяют точки отрезками прямых.
Полигон относительных частот строится аналогично, за исключением того, что на оси ординат откладываются относительные частоты .
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которой служат частичные интервалы длиною h, а высоты равны отношению . Для построения гистограммы частот на оси абсцисс откладывают частичные интервалы, а над ними проводят отрезки, параллельные оси абсцисс на расстоянии (высоте) . Площадь i–го прямоугольника равна – сумме частот вариант i–о интервала, поэтому площадь гистограммы частот равна сумме всех частот, т.е. объему выборки.


Эмпирическая функция распределения
где n x - число выборочных значений, меньших x ; n - объем выборки.
22Определим основные понятия математической статистики
. Основные понятия математической статистики. Генеральная совокупность и выборка. Вариационный ряд, статистический ряд. Группированная выборка. Группированный статистический ряд. Полигон частот. Выборочная функция распределения и гистограмма.
Генеральная совокупность – все множество имеющихся объектов.
Выборка – набор объектов, случайно отобранных из генеральной совокупности.
Последовательность вариант, записанных в порядке возрастания, называют вариационным рядом, а перечень вариант и соответствующих им частот или относительных частот – стати-стическим рядом :чайно отобранных из генеральной совокупности.
Полигоном частот называют ломаную линию, отрезки которой соединяют точки .
Гистограммой частот называют ступенчатую фигуру, состоящую из прямоугольников, основаниями которой служат частичные интервалы длиною h, а высоты равны отношению .
Выборочной (эмпирической) функцией распределения называют функцию F* (x ), определяющую для каждого значения х относительную частоту события X < x.
Если исследуется некоторый непрерывный признак, то вариационный ряд может состоять из очень большого количества чисел. В этом случае удобнее использовать группированную выборку . Для ее получения интервал, в котором заключены все наблюдаемые значения признака, разбивают на несколько равных частичных интервалов длиной h , а затем находят для каждого частичного интервала n i – сумму частот вариант, попавших в i -й интервал.
20. Под законом больших чисел не следует понимать какой-то один общий закон, связанный с большими числами. Закон больших чисел - это обобщенное название нескольких теорем, из которых следует, что при неограниченном увеличении числа испытаний средние величины стремятся к некоторым постоянным.
К ним относятся теоремы Чебышева и Бернулли. Теорема Чебышева является наиболее общим законом больших чисел.
В основе доказательства теорем, объединенных термином "закон больших чисел", лежит неравенство Чебышева, по которому устанавливается вероятность отклонения от ее математического ожидания:
![]()
19Распределение Пирсона (хи - квадрат) – распределение случайной величины
где случайные величины X 1 , X 2 ,…, X n независимы и имеют одно и тоже распределение N (0,1). При этом число слагаемых, т.е. n , называется «числом степеней свободы» распределения хи – квадрат.
Распределение хи-квадрат используют при оценивании дисперсии (с помощью доверительного интервала), при проверке гипотез согласия, однородности, независимости,
Распределение t Стьюдента – это распределение случайной величины
где случайные величины U и X независимы, U имеет распределение стандартное нормальное распределение N (0,1), а X – распределение хи – квадрат с n степенями свободы. При этом n называется «числом степеней свободы» распределения Стьюдента.
Его применяют при оценивании математического ожидания, прогнозного значения и других характеристик с помощью доверительных интервалов, по проверке гипотез о значениях математических ожиданий, коэффициентов регрессионной зависимости,
Распределение Фишера – это распределение случайной величины
Распределение Фишера используют при проверке гипотез об адекватности модели в регрессионном анализе, о равенстве дисперсий и в других задачах прикладной статистики
18Линейная регрессия является статистическим инструментом, используемым для прогнозирования будущих цен исходя из прошлых данных, и обычно применяется, чтобы определить, когда цены являются перегретыми. Используется метод наименьшего квадрата для построения «наиболее подходящей» прямой линии через ряд точек ценовых значений. Ценовыми точками, используемыми в качестве входных данных, может быть любое из следующих значений: открытие, закрытие, максимум, минимум,
17. двумерной случайной величиной называют упорядоченный набор из двух случайных величин или .
Пример.Подбрасываются два игральных кубика. – число очков, выпавших на первом и втором кубиках соответственно
Универсальный способ задания закона распределения двумерной случайной величины – это функция распределения.
15.м.о Дискретные случайные величины
Свойства:
1) M (C ) = C , C - постоянная;
2) M (CX ) = CM (X );
3) M (X 1 + X 2 ) = M (X 1 ) + M (X 2 ), где X 1 , X 2 - независимые случайные величины;
4) M (X 1 X 2 ) = M (X 1 )M (X 2 ).
Математическое ожидание суммы случайных величин равно сумме их математических ожиданий, т.е.
Математическое ожидание разности случайных величин равно разности их математических ожиданий, т.е.
Математическое ожидание произведения случайных величин равно произведению их математических ожиданий, т.е.
Если все значения случайной величины увеличить (уменьшить) на одно и тоже число С, то ее математическое ожидание увеличится (уменьшиться) на это же число
14. Показательный (экспоненциальный ) закон распределения X имеет показательный (экспоненциальный) закон распределения с параметром λ >0, если ее плотность вероятности имеет вид:
![]()
Математическое ожидание: .
Дисперсия: .
Показательный закон распределения играет большую роль в теории массового обслуживания и теории надежности.
13. Нормальный закон распределения характеризуется частотой отказов a (t) или плотностью вероятности отказов f (t) вида:
 , (5.36)
, (5.36)
где σ– среднеквадратическое отклонение СВ x ;
mx – математическое ожидание СВ x . Этот параметр часто называют центром рассеивания или наиболее вероятным значением СВ Х .
x – случайная величина, за которую можно принять время, значение тока, значение электрического напряжения и других аргументов.
Нормальный закон – это двухпараметрический закон, для записи которого нужно знать mx и σ.
Нормальное распределение (распределение Гаусса) используется при оценке надежности изделий, на которые воздействует ряд случайных факторов, каждый из которых незначительно влияет на результирующий эффект
12. Равномерный закон распределения . Непрерывная случайная величина X имеет равномерный закон распределения на отрезке [a , b ], если ее плотность вероятности постоянна на этом отрезке и равна нулю вне его, т.е.

Обозначение: .
Математическое ожидание: .
Дисперсия: .
Случайная величина Х , распределенная по равномерному закону на отрезке называется случайным числом от 0 до 1. Она служит исходным материалом для получения случайных величин с любым законом распределения. Равномерный закон распределения используется при анализе ошибок округления при проведении числовых расчетов, в ряде задача массового обслуживания, при статистическом моделировании наблюдений, подчиненных заданному распределению.
11. Определение. Плотностью распределения вероятностей непрерывной случайной величины Х называется функция f(x) – первая производная от функции распределения F(x).
Плотность распределения также называют дифференциальной функцией . Для описания дискретной случайной величины плотность распределения неприемлема.
Смысл плотности распределения состоит в том, что она показывает как часто появляется случайная величина Х в некоторой окрестности точки х при повторении опытов.
После введения функций распределения и плотности распределения можно дать следующее определение непрерывной случайной величины.
10. Плотность вероятности, плотность распределения вероятностей случайной величины x, - функция p(x) такая, что
и при любых a < b вероятность события a < x < b равна
.
Если p(x) непрерывна, то при достаточно малых ∆x вероятность неравенства x < X < x+∆x приближенно равна p(x) ∆x (с точностью до малых более высокого порядка). Функция распределения F(x) случайной величины x, связана с плотностью распределения соотношениями
и, если F(x) дифференцируема, то![]()
Методы обработки ЭД опираются на базовые понятия теории вероятностей и математической статистики. К их числу относятся понятия генеральной совокупности, выборки, эмпирической функции распределения .
Под генеральной совокупностью понимают все возможные значения параметра, которые могут быть зарегистрированы в ходе неограниченного по времени наблюдения за объектом. Такая совокупность состоит из бесконечного множества элементов. В результате наблюдения за объектом формируется ограниченная по объему совокупность значений параметра x 1 , x 2 , …, x n . С формальной точки зрения такие данные представляют собой выборку из генеральной совокупности .
Будем считать, что выборка содержит полные наработки до системных событий (цензурирование отсутствует). Наблюдаемые значения x i называют вариантами , а их количество – объемом выборки n . Для того чтобы по результатам наблюдения можно было делать какие-либо выводы, выборка должна быть репрезентативной (представительной), т. е. правильно представлять пропорции генеральной совокупности. Это требование выполняется, если объем выборки достаточно велик, а каждый элемент генеральной совокупности имеет одинаковую вероятность попасть в выборку.
Пусть в полученной выборке значение x 1 параметра наблюдалось n 1 раз, значение x 2 – n 2 раз, значение x k – n k раз, n 1 +n 2 + … +n k =n .
Совокупность значений, записанных в порядке их возрастания, называют вариационным рядом , величины n i – частотами , а их отношения к объему выборки n i =n i /n – относительными частотами (частостями). Очевидно, что сумма относительных частот равна единице.
Под распределением понимают соответствие между наблюдаемыми вариантами и их частотами или частостями. Пусть n
x
– количество наблюдений, при которых случайные значения параметра Х
меньше x.
Частость события X
распределения: F n (x ) неубывающая функция, ее значения принадлежат отрезку ;
если x 1 – наименьшее значение параметра, а x k – наибольшее, то F n (x )= 0, когда x <x 1 , и F п (x k )= 1, когда x >=x k .
Функция F n (x ) определяется по ЭД, поэтому ее называют эмпирической функцией распределения . В отличие от эмпирической функции F n (x ) функцию распределения F (x ) генеральной совокупности называют теоретической функцией распределения, она характеризует не частость, а вероятность события X <x . Из теоремы Бернулли вытекает, что частость F n (x ) стремится по вероятности к вероятности F (x ) при неограниченном увеличении n . Следовательно, при большом объеме наблюдений теоретическую функцию распределения F (x ) можно заменить эмпирической функцией F n (x ).
График эмпирической функции F n (x ) представляет собой ломаную линию. В промежутках между соседними членами вариационного ряда F n (x ) сохраняет постоянное значение. При переходе через точки оси x , равные членам выборки, F n (x ) претерпевает разрыв, скачком возрастая на величину 1/n , а при совпадении l наблюдений – на l /n .
Пример 2.1 . Построить вариационный ряд и график эмпирической функции распределения по результатам наблюдений, табл. 2.1.
Таблица 2.1
Искомая эмпирическая функция, рис. 2.1:

Рис. 2.1. Эмпирическая функция распределения
При большом объеме выборки (понятие «большой объем» зависит от целей и методов обработки, в данном случае будем считать п большим, если n >40) в целях удобства обработки и хранения сведений прибегают к группированию ЭД в интервалы. Количество интервалов следует выбрать так, чтобы в необходимой мере отразилось разнообразие значений параметра в совокупности и в то же время закономерность распределения не искажалась случайными колебаниями частот по отдельным разрядам. Существуют нестрогие рекомендации по выбору количества y и размера h таких интервалов, в частности:
в каждом интервале должно находиться не менее 5 – 7 элементов. В крайних разрядах допустимо всего два элемента;
количество интервалов не должно быть очень большим или очень маленьким. Минимальное значение y должно быть не менее 6 – 7. При объеме выборки, не превышающем несколько сотен элементов, величину y задают в пределах от 10 до 20. Для очень большого объема выборки (n >1000) количество интервалов может превышать указанные значения. Некоторые исследователи рекомендуют пользоваться соотношением y=1,441*ln(n )+1;
при относительно небольшой неравномерности длины интервалов удобно выбирать одинаковыми и равными величине
h= (x max – x min)/y,
где x max – максимальное и x min – минимальное значение параметра. При существенной неравномерности закона распределения длины интервалов можно задавать меньшего размера в области быстрого изменения плотности распределения;
при значительной неравномерности лучше в каждый разряд назначать примерно одинаковое количество элементов выборки. Тогда длина конкретного интервала будет определять крайними значениями элементов выборки, сгруппироваными в этот интервал, т.е. будет различна для разных интервалов (в этом случае при построении гистограммы нормировка по длине интервала обязательна - в противном случае высота каждого элемента гистограммы будет одинакова).
Группирование результатов наблюдений по интервалам предусматривает: определение размаха изменений параметра х ; выбор количества интервалов и их величины; подсчет для каждого i- го интервала [x i –x i +1 ] частоты n i или относительной частоты (частости n i ) попадания варианты в интервал. В результате формируется представление ЭД в виде интервального или статистического ряда .
Графически статистический ряд отображают в виде гистограммы, полигона и ступенчатой линии. Часто гистограмму представляют как фигуру, состоящую из прямоугольников, основаниями которых служат интервалы длиною h , а высоты равны соответствующей частости. Однако такой подход неточен. Высоту i- го прямоугольника z i следует выбрать равной n i / (nh ). Такую гистограмму можно интерпретировать как графическое представление эмпирической функции плотности распределения f n (x ), в ней суммарная площадь всех прямоугольников составит единицу. Гистограмма помогает подобрать вид теоретической функции распределения для аппроксимации ЭД.
Полигоном называют ломаную линию, отрезки которой соединяют точки с координатами по оси абсцисс, равными серединам интервалов, а по оси ординат – соответствующим частостям. Эмпирическая функция распределения отображается ступенчатой ломаной линией: над каждым интервалом проводится отрезок горизонтальной линии на высоте, пропорциональной накопленной частости в текущем интервале. Накопленная частость равна сумме всех частостей, начиная с первого и до данного интервала включительно.
Пример 2.2 . Имеются результаты регистрации значений затухания сигнала x i на частоте 1000 Гц коммутируемого канала телефонной сети. Эти значения, измеренные в дБ, в виде вариационного ряда представлены в табл. 2.3. Необходимо построить статистический ряд.
Таблица 2.3
| i | |||||||||||
| x i | 25,79 | 25,98 | 25,98 | 26,12 | 26,13 | 26,49 | 26,52 | 26,60 | 26,66 | 26,69 | 26,74 |
| i | |||||||||||
| x i | 26,85 | 26,90 | 26,91 | 26,96 | 27,02 | 27,11 | 27,19 | 27,21 | 27,28 | 27,30 | 27,38 |
| i | |||||||||||
| x i | 27,40 | 27,49 | 27,64 | 27,66 | 27,71 | 27,78 | 27,89 | 27,89 | 28,01 | 28,10 | 28,11 |
| i | |||||||||||
| x i | 28,37 | 28,38 | 28,50 | 28,63 | 28,67 | 28,90 | 28,99 | 28,99 | 29,03 | 29,12 | 29,28 |
Решение . Количество разрядов статистического ряда следует выбрать минимальным, чтобы обеспечить достаточное количество попаданий в каждый из них, возьмем y = 6. Определим размер разряда
h = (x max – x min)/y =(29,28 – 25,79)/6 = 0,58.
Сгруппируем наблюдения по разрядам, табл. 2.4.
Таблица 2.4
| i | ||||||
| x i | 25,79 | 26,37 | 26,95 | 27,5 3 | 28,12 | 28,70 |
| n i | ||||||
| n i =n i /n | 0,114 | 0,205 | 0,227 | 0,205 | 0,11 4 | 0,136 |
| z i = n i /h | 0,196 | 0,353 | 0,392 | 0,353 | 0,196 | 0,235 |
На основе статистического ряда построим гистограмму, рис. 2.2, и график эмпирической функции распределения, рис. 2.3.
График эмпирической функции распределения, рис. 2.3, отличается от графика, представленного на рис. 2.1 равенством шага изменения варианты и величиной шага приращения функции (при построении по вариационному ряду шаг приращения кратен
1/ n , а по статистическому ряду – зависит от частости в конкретном разряде).

Рассмотренные представления ЭД являются исходными для последующей обработки и вычисления различных параметров.
Лекция 13. Понятие о статистических оценках случайных величин
Пусть известно статистическое распределение частот количественного признака X. Обозначим через число наблюдений, при которых наблюдалось значение признака, меньшее x и через n – общее число наблюдений. Очевидно, относительная частота события X < x равна и является функцией x. Так как эта функция находится эмпирическим (опытным) путем, то ее называют эмпирической.
Эмпирической функцией распределения (функцией распределения выборки) называют функцию , определяющую для каждого значения x относительную частоту события X < x. Таким образом, по определению ,где - число вариант, меньших x, n – объем выборки.
В отличие от эмпирической функции распределения выборки, функцию распределения генеральной совокупности называют теоретической функцией распределения. Различие между этими функциями состоит в том, что теоретическая функцияопределяет вероятность события X < x, тогда как эмпирическая – относительную частоту этого же события.
При росте n относительная частота события X < x, т.е. стремится по вероятности к вероятности этого события. Иными словами
Свойства эмпирической функции распределения :
1) Значения эмпирической функции принадлежат отрезку
2) - неубывающая функция
3) Если - наименьшая варианта, то = 0 при , если - наибольшая варианта, то =1 при .
Эмпирическая функция распределения выборки служит для оценки теоретической функции распределения генеральной совокупности.
Пример . Построим эмпирическую функцию по распределению выборки:
| Варианты | |||
| Частоты |
Найдем объем выборки: 12+18+30=60. Наименьшая варианта равна 2, поэтому =0 при x £ 2. Значение x<6, т.е. , наблюдалось 12 раз, следовательно, =12/60=0,2 при 2< x £6. Аналогично, значения X < 10, т.е. и наблюдались 12+18=30 раз, поэтому =30/60 =0,5 при 6< x £10. Так как x=10 – наибольшая варианта, то =1 при x> 10. таким образом, искомая эмпирическая функция имеет вид:
Важнейшие свойства статистических оценок
Пусть требуется изучить некоторый количественный признак генеральной совокупности. Допустим, что из теоретических соображений удалось установить, какое именно распределение имеет признак и необходимо оценить параметры, которыми оно определяется. Например, если изучаемый признак распределен в генеральной совокупности нормально, то нужно оценить математическое ожидание и среднее квадратическое отклонение; если признак имеет распределение Пуассона – то необходимо оценить параметр l.
Обычно имеются лишь данные выборки, например значения количественного признака , полученные в результате n независимых наблюдений. Рассматривая как независимые случайные величины можно сказать, что найти статистическую оценку неизвестного параметра теоретического распределения – значит найти функцию от наблюдаемых случайных величин, которая дает приближенное значение оцениваемого параметра. Например, для оценки математического ожидания нормального распределения роль функции выполняет среднее арифметическое
Для того чтобы статистические оценки давали корректные приближения оцениваемых параметров, они должны удовлетворять некоторым требованиям, среди которых важнейшими являются требования несмещенности и состоятельности оценки.
Пусть - статистическая оценка неизвестного параметра теоретического распределения. Пусть по выборке объема n найдена оценка . Повторим опыт, т.е. извлечем из генеральной совокупности другую выборку того же объема и по ее данным получим другую оценку . Повторяя опыт многократно, получим различные числа . Оценку можно рассматривать как случайную величину, а числа - как ее возможные значения.
Если оценка дает приближенное значение с избытком , т.е. каждое число больше истинного значения то, как следствие, математическое ожидание (среднее значение) случайной величины больше, чем :. Аналогично, если дает оценку с недостатком , то .
Таким образом, использование статистической оценки, математическое ожидание которой не равно оцениваемому параметру, привело бы к систематическим (одного знака) ошибкам. Если, напротив, , то это гарантирует от систематических ошибок.
Несмещенной называют статистическую оценку , математическое ожидание которой равно оцениваемому параметру при любом объеме выборки .
Смещенной называют оценку, не удовлетворяющую этому условию.
Несмещенность оценки еще не гарантирует получения хорошего приближения для оцениваемого параметра, так как возможные значения могут быть сильно рассеяны вокруг своего среднего значения, т.е. дисперсия может быть значительной. В этом случае найденная по данным одной выборки оценка, например , может оказаться значительно удаленной от среднего значения ,а значит, и от самого оцениваемого параметра.
Эффективной называют статистическую оценку, которая, при заданном объеме выборки n, имеет наименьшую возможную дисперсию .
При рассмотрении выборок большого объема к статистическим оценкам предъявляется требование состоятельности .
Состоятельной называется статистическая оценка, которая при n®¥ стремится по вероятности к оцениваемому параметру. Например, если дисперсия несмещенной оценки при n®¥ стремится к нулю, то такая оценка оказывается и состоятельной.